계좌에 입금한 내 돈이 사라진다?
재욱이와 찬수가 은행 계좌에 돈을 넣고 있어요. 재욱이의 계좌는 현재 3만원이 있고, 현금 1천원을 추가로 입금하려고 해요. 찬수는 재욱에게 전에 빌렸던 돈 2천원을 송금하려고 해요.
재욱이와 찬수는 재욱이의 계좌에 돈을 비슷한 시기에 (거의 동시에) 입금했어요. 하지만 재욱이의 계좌 잔액은 3만 3천원이 아닌 3만 2천원이 됐어요. 어떻게 된 일일까요?
입출금 프로그램이 어떻게 작동하는지 자세히 살펴볼게요.
재욱의 경우)
[재욱] A1. 계좌 금액을 받아옴
[재욱] A2. 계좌 금액에 1천원을 더함
[재욱] A3. 더한 값을 재욱의 계좌 잔액으로 저장함찬수의 경우)
[찬수] B1. 재욱의 계좌 금액을 받아옴
[찬수] B2. 계좌 금액에 2천원을 더함
[찬수] B3. 더한 값을 재욱의 계좌 잔액으로 저장함이제 두 과정이 (거의) 동시에 일어난다면? >>
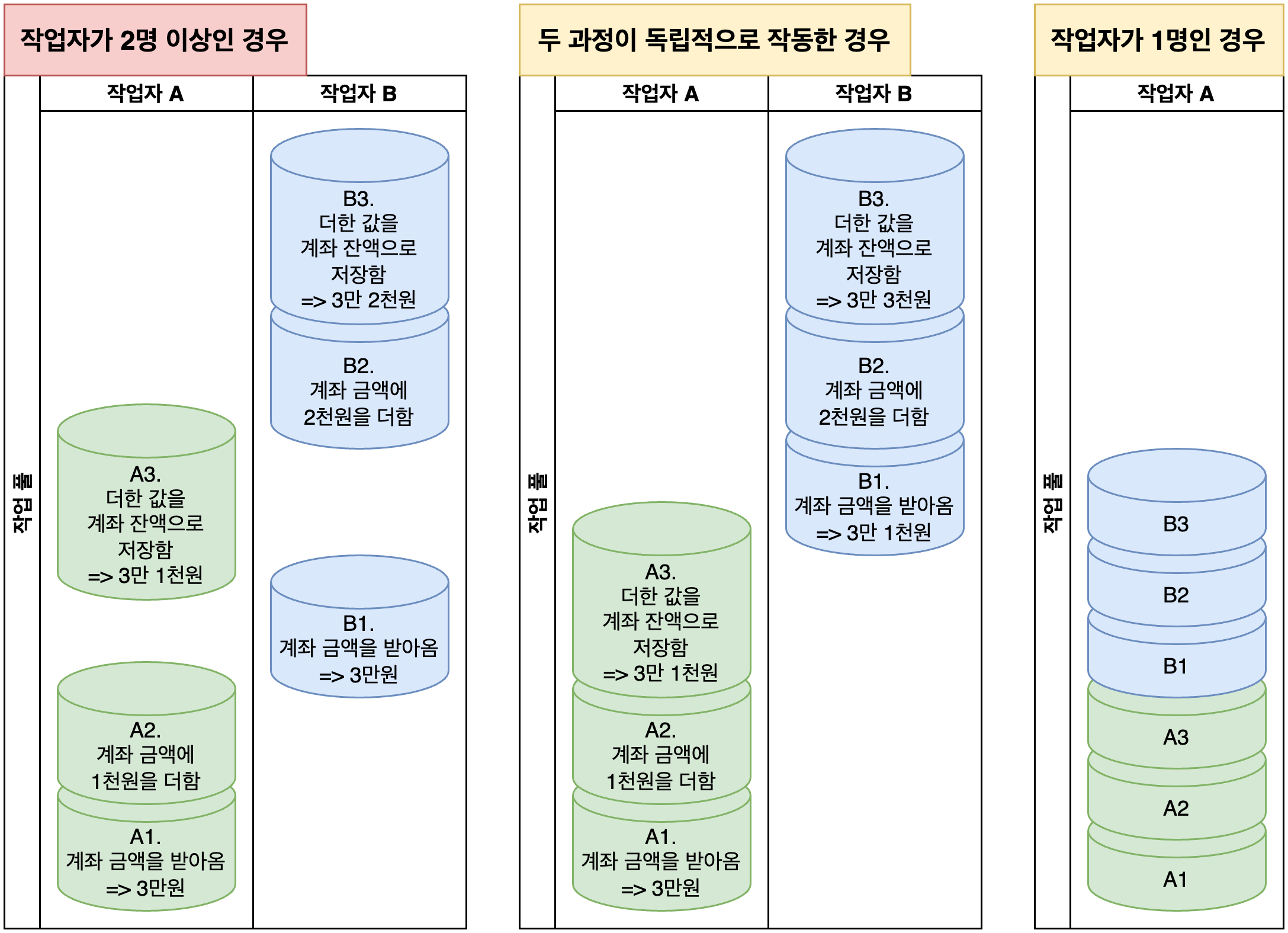
왜 이렇게 된 것일까요?
- 두 과정이 독립적으로 작동하거나
- 작업자가 1명이면 문제가 발생하지 않아요.
그런데 둘은 거의 동시에 돈을 입금해서 실제로 프로그램의 작동 순서가 아래와 같이 되어 결과적으로 재욱이가 입금한 현급 1천원이 누락되는 일이 벌어졌습니다. 서로 계좌 금액에 대해 ‘경쟁’하는 상태가 벌어졌고, 작업을 수행하는 순서에 따라 결과가 달라지게 되어 버린 것이죠.
컴퓨터에서의 경쟁 상태
이처럼 컴퓨터에서 한 자원을 가지고 여러 대상이 공유 자원에 대해 동시에 접근할 때, 여러 대상들이 작업을 수행하는 순서에 따라 결과가 달라질 수 있어요. 이렇게 여러 대상들이 한 자원을 가지고 경쟁하는 것을 경쟁 상태 = ‘Race Condition’이라고 합니다.
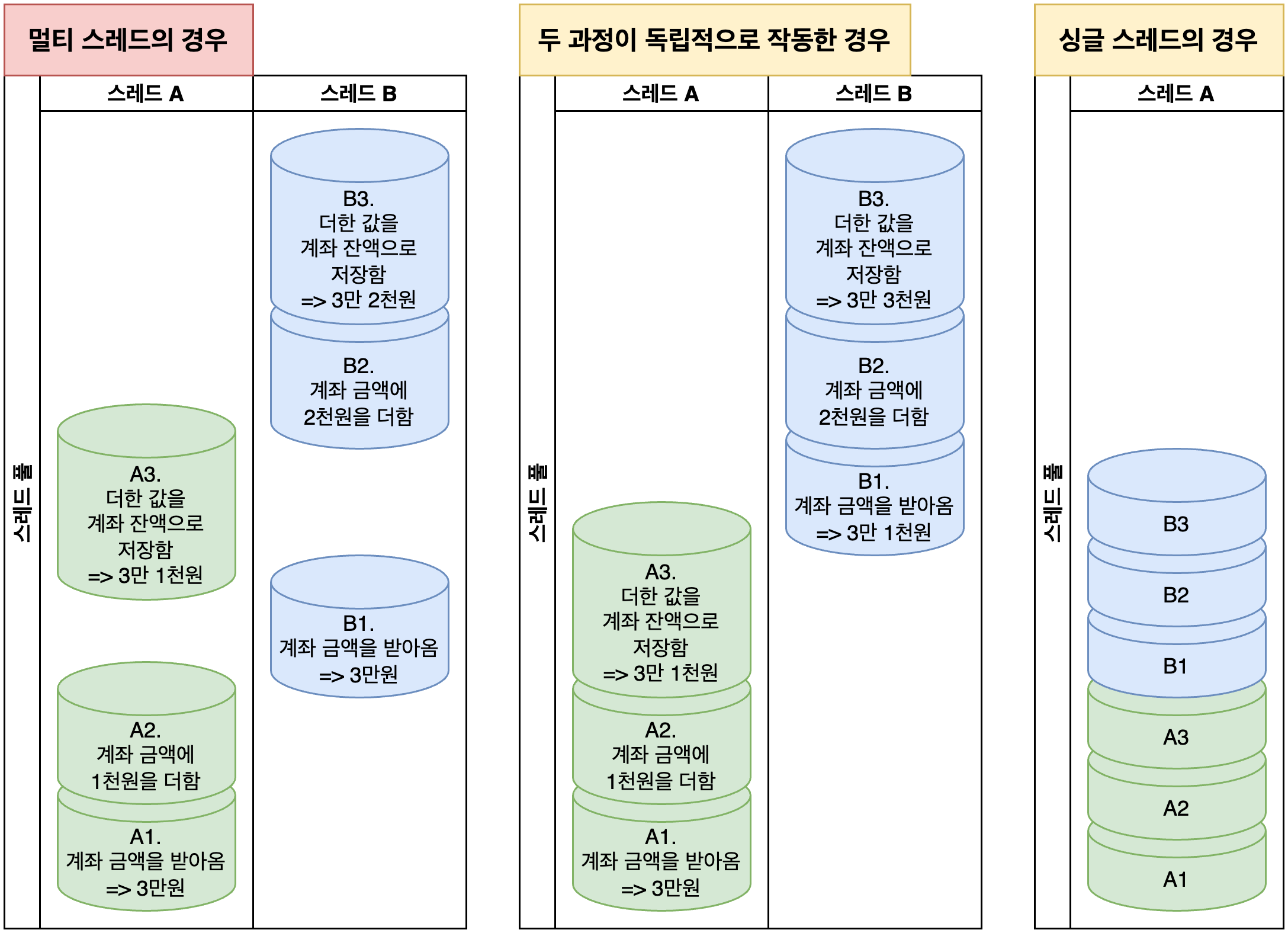
- 스레드는 컴퓨터 내에서 실행되는 작업의 흐름 단위를 말합니다. 처음 예시에서 ‘작업자’를 뜻해요.
- 싱글 스레드 (작업자가 1명)에서는 작업 흐름 단위가 하나이기 때문에 Race Condition이 발생할 염려가 없습니다.
- 멀티 스레드 (작업자가 2명 이상)에서는 반대로 Race Condition이 발생할 수 있습니다.
따라서 이러한 경쟁 상태에서 자원을 안전하게 처리하기 위해서, 우리는 원자적 (Atomic) 행위를 실행하여 무결성을 보장해요. Atomic하다는 것은 원자가 더 작게 쪼개질 수 없다는 의미에서 파생되어서 → 그 사이에 다른일이 일어날 수 없다는 뜻으로 이해하면 돼요.
원자적 행위를 위한 구현
그렇다면 자원을 안전하게 처리하기 위해서 어떻게 원자적 행위를 실현할 수 있을까요? 소프트웨어 내에서 Race Condition을 방지하기 위해 구현된 기법 중 대표적인 방법으로는 세마포어와 뮤텍스를 들 수 있어요.
1. 화장실이 한개가 있음, 화장실을 들어가려면 열쇠가 필요함
2. 화장실에 A가 들어감
3. 밖에서 B가 기다리고 있음
4. 용무가 끝나면 A가 화장실에서 나와 열쇠를 반납함
5. 열쇠를 기다리던 B는 반납된 열쇠를 가지고 화장실에 들어감이렇게 Key를 기반으로 Race Condition을 방지하는 방법이 있어요. 이를 Mutex (뮤텍스)라고 해요. 이렇게 공유가 불가능한 한가지 자원의 동시 접근을 막아 ‘상호 배제’를 달성해요.
1. 화장실이 두개가 있음, 화장실 밖에는 빈 화장실이 몇개인지를 알려주는 전광판이 있음
2. 화장실에 A가 들어감 (전광판은 1로 바뀜)
3. 화장실에 B가 들어감 (전광판은 0으로 바뀜)
4. C가 화장실에 가고 싶은데 전광판 숫자가 0이어서 들어가지 못함
5. A와 B 둘중 아무나 용무를 보고 나와서 전광판 숫자가 1 이상으로 바뀌면 C가 들어감 (전광판은 0으로 바뀜)이렇게 공통으로 관리하는 하나의 값을 이용해 상호 배제를 달성하는 방법이 있어요. 이를 Semaphore (세마포어)라고 해요. 뮤텍스와 달리 두 개 이상의 공유 자원에 대해 상호 배제를 달성하고 싶을 때 주로 사용해요.
다만 이런 원자적 행위에는 한가지 유의할 점이 있어요.
위 예시들처럼 기다리는 애들이 생긴다는 것은 작업이 빨리 처리되지 못한다는 의미에요.
만약 뮤텍스의 예시에서 A가 작업을 다 마치고 열쇠를 반납하지 않는다면 어떻게 될까요? B는 그 자리에서 열쇠가 반납될 때까지 무한정 기다릴 거에요.
⇒ 즉 이러한 원자적 행위는 처리 성능의 저하를 동반할 수 밖에 없고, 위와 같은 불상사가 발생하지 않도록 신경써서 설계해야 합니다.
데이터베이스에서의 원자적 행위
트랜잭션
흔히 말하는 데이터베이스 분야에서의 ‘트랜잭션’도 원자적 행위 중 하나에요.
원래는 원자성이 없는 명령어들을 묶어서 하나의 최소 실행 단위로 만든 것을 트랜잭션이라고 해요.
- 원자성이 없는 상태의 명령어로 데이터에 접근한다면 위에 살펴본 경우들처럼 경쟁 상태 (Race Condition)에 처할 수 있어요.
트랜잭션은 전부 처리되거나 아예 처리되지 않아야 해요.
- 작업 처리 도중에 사용 중인 자원이 다른 작업에 의해 수정되어 데이터가 망가졌다고 가정할 때, 그것은 비정합하여 잘못된 데이터로 취급할 수 있어요. 잘못된 데이터로는 작업이 아예 처리가 되어서는 안돼요. 그렇기 때문에 트랜잭션은 전부 처리되거나 아예 처리되지 않아야 해요. 말 그대로 작업의 최소 실행 단위인 것이죠.
트랜잭션에서 원자성을 보장하기 위해서는 트랜잭션을 수행할 때 해당 명령어를 수행하는 부분의 데이터 (⇒ 공유 자원)에 락을 걸어요. 락을 걸어서 다른 대상이 그 데이터에 접근하지 못하게 막고 데이터의 정합성을 보장해요.
락의 형태
트랜잭션을 처리할 때 여러 방법으로 락을 걸 수 있겠지만, 데이터베이스에서 락을 관리하는 형태에 따라 크게 두가지 개념으로 나눌 수 있어요.
비관적 락
- 비관적 락의 경우 트랜잭션이 시작될 때 락을 걸고 명령을 수행하고 락을 푸는 방식을 얘기하는데, ‘같은 공유자원에 접근하지 않아 충돌나는 경우가 많지 않을 것’라고 비관적으로 생각하기 때문에 비관적 락이라고 불러요.
낙관적 락
- 낙관적 락은 일단 트랜잭션을 수행하고, 다른 트랜잭션과 충돌이 발생했을 경우 충돌난 트랜잭션을 롤백하는 방식을 낙관적 락이라고 합니다. ‘같은 공유 자원에 접근하는 경우가 거의 없을 것’이라고 낙관적으로 생각해서 낙관적 락이라고 불러요.
MySQL에서의 락
가장 범용적으로 쓰이는 데이터베이스인 MySQL과 MariaDB에서도 뮤텍스와 비슷하게 Lock을 구현하여 데이터 정합성을 보장합니다.
- A, B, C라는 데이터가 DB에 담겨있다면 C에 접근하는 경우 C에 Lock을 걸어 다른 요소들이 접근할 수 없게 하고, 작업이 끝난다면 Lock을 풀어서 그제서야 다른 데이터가 접근하도록 함으로서 정합성을 보장해요.
MySQL에서의 락은 크게 1. MySQL 엔진 레벨 락과 2. 스토리지 엔진 레벨 락이 있는데,
- MySQL 엔진 레벨의 경우 MySQL 애플리케이션 층에서 동작하는 고수준의 락으로 사용자가 명시적으로 직접 락을 설정하고 해제하여 관리할 수 있음
- 스토리지 엔진 레벨의 경우 저수준의 락으로 내부적으로 데이터를 처리할 때 어떻게 락을 걸어서 동작하는 지를 말함
MySQL과 MariaDB에서 제일 많이 사용되는 스토리지 엔진은 InnoDB입니다. InnoDB의 경우 기본적으로 비관적 락을 사용해요.
InnoDB에서의 락과 트랜잭션
- InnoDB의 경우 실제 레코드가 아닌 인덱스 레코드에다가 락을 건다는 특징이 있습니다.
- 인덱스가 없는 데이터일 경우 자체적으로 생성된 클러스터 인덱스를 통해 락을 겁니다.
인덱스에 락을 걸기 때문에 인덱스 자체가 동시성 제어에 영향을 미쳐요. 따라서 인덱스를 설계할 때는 동시성을 고려해서 설계해야 해요.
InnoDB의 락은 레코드 락, 갭 락, 넥스트 키 락, 오토 인크리먼트 락이 있어요.
레코드 락
- 레코드 락은 해당하는 레코드의 인덱스 레코드에 락을 걸어 잠그는 것을 말합니다.
사례
SELECT 가격 FROM 결제_기록 WHERE 결제ID = 2 FOR UPDATE;
// 결제 ID가 Unique 한 경우, 해당 결제 ID에 대한 레코드만 락이 걸림갭 락
- 특정 레코드에서 레코드까지 특정 인덱스 레코드에 인접한 주위 인덱스 레코드의 갭까지 락을 걸어 사이의 간격을 잠그는 것을 말합니다. 중간에 다른 요소가 삽입되지 않도록 막습니다.
사례
| 결제ID | 가격 |
| 2 | 1000 |
| 8 | 1000 |
SELECT 가격 FROM 결제_기록 WHERE 결제ID BETWEEN 4 AND 5 FOR UPDATE;
// 결제 ID가 3~5인 결제 기록의 가격들을 가져옴
// 이때 갭은 2~3 (최초 레코드 이전의 갭)과 6~8 (마지막 레코드 이후의 갭)이 되어
// 다른 요소가 삽입되지 않도록 2~3번과 6~8번 레코드가 잠깁니다.넥스트 키 락
- 레코드 락과 갭 락을 합친 형태로, 인덱스 레코드도 잠그고 그 앞뒤의 인접한 인덱스 레코드까지 락을 걸어 사이의 간격까지 잠그는 것을 말합니다.
사례
| 결제ID | 가격 |
| 2 | 1000 |
| 4 | 1000 |
| 5 | 1000 |
| 8 | 1000 |
SELECT 가격 FROM 결제_기록 WHERE 결제ID BETWEEN 4 AND 5 FOR UPDATE;
// 결제 ID가 3~5인 결제 기록의 가격들을 가져옴
// 1. [레코드 락]
// 결제 ID가 4, 5인 레코드가 잠깁니다.
// 2. [갭 락]
// 이때 갭은 2~3 (최초 레코드 이전의 갭)과 6~8 (마지막 레코드 이후의 갭)이 되어
// 다른 요소가 삽입되지 않도록 2~3번과 6~8번 레코드가 잠깁니다.오토 인크리먼트 락
- 자동으로 증가하는 숫자 컬럼 (AUTO_INCREMENT)의 경우 Insert 시 숫자가 중복되면 안되기 때문에, 요청이 오면 내부적으로 락을 걸어 충돌을 방지하는 것을 말합니다.
InnoDB에서 락으로 인한 성능 저하 줄이기
아래와 같은 간단한 쿼리를 사용할 때에도 인덱스 설계를 잘못했다면 성능 저하가 발생할 수 있어요.
SELECT 가격 FROM 결제_기록 WHERE 고객사ID = '1212' FOR UPDATE; // 100건
SELECT 가격 FROM 결제_기록 WHERE 고객사ID = '1212' AND 결제시간 = 20240502 FOR UPDATE; // 1건
// 특정 고객사의, 특정 결제 시간의 가격 데이터를 불러온다.
// 이때 고객사 ID에 인덱스가 걸려있고 결제 시간에 인덱스가 걸려있지 않다면
// 특정 결제 시간에 해당하지 않는, 고객사 ID가 1212인 모든 결제에 대해 락이 걸린다. (100건)
// -> 성능저하- 실제로는 1건이 조회되지만 락은 100건에 대해 전부 일어나는 사태가 벌어지는 것이에요.
- 속도를 개선하려면 인덱스를 결제 시간에도 생성해서, 실제로 조회하는 레코드에만 락을 걸 수 있도록 하는 방식이 있어요.
이론 실제로 검증해보기
실제로도 그런지 속도를 비교해보기 위해, 테이블을 만들고 랜덤으로 Mockup 데이터를 생성해 2652개의 데이터가 담긴 테이블을 생성했습니다.
락으로 인한 성능저하는 동시 다발적으로 쿼리를 실행할 때 일어나므로 쿼리를 여러번 병렬로 실행하는 프로그램을 Go로 작성했어요.
package main
import (
"database/sql"
"log"
"strings"
"sync"
"time"
_ "github.com/go-sql-driver/mysql"
)
func main() {
// 데이터베이스 설정
db, err := sql.Open("mysql", "user:pwd@tcp(example.com:3306)/jaewook_test_db")
if err != nil {
log.Fatal(err)
}
defer db.Close()
numGoroutines := 80
query := "SELECT 가격 FROM 결제_기록 WHERE 고객사ID = 'jaewook' AND 가격 = 2900 FOR UPDATE"
wg := sync.WaitGroup{}
times := make([]time.Duration, numGoroutines)
for i := 0; i < numGoroutines; i++ {
wg.Add(1)
go func(index int) {
d := executeQuery(db, index, query)
times = append(times, d)
wg.Done()
}(i)
}
wg.Wait()
// 평균 구하기
avg := 0.0
for _, t := range times {
avg += float64(t)
}
avg /= float64(numGoroutines)
avg /= float64(time.Millisecond) // 밀리세컨드로 변환
log.Printf("평균 실행 시간: %v\n", query, avg)
}
func executeQuery(db *sql.DB, index int, query string) time.Duration {
start := time.Now()
_, err := db.Exec(query)
if err != nil {
log.Printf("쿼리 #%d 실행 오류: %v\n", index+1, err)
return 0
}
duration := time.Since(start)
return duration
}가정
- 실험에 사용하는 모든 쿼리는
SELECT FOR UPDATE로 한다.
- 실험에 사용하는 모든 쿼리의
WHERE은 2개의 조건으로 한다.
- 쿼리 속도에 영향을 미치는 요인은 아래 두가지로 한다.
- 단일/복합 인덱스에 의한 요인
- 단일/복합 인덱스의 사용 시 내부적인 락에 의한 요인 (이하 락에 의한 요인)
가설
- 단일 인덱스보다 복합 인덱스가 있을 때의 실행 속도가 더 빠를 것이다.
- 쿼리를 동시에 실행하면 락에 의해 실행 속도가 느려질 것이다.
- 쿼리를 동시에 실행할 때 복합 인덱스라면, 불필요한 락이 사라지기 때문에 실행 속도가 빨라질 것이다. ↔ 쿼리를 동시에 실행할 때 단일 인덱스라면, 불필요한 락이 걸리기 때문에 실행 속도가 느려질 것이다.
- ⇒ 단일 인덱스일 때와 복합 인덱스 일 때의 실행 시간 개선 비율은, 쿼리를 하나 실행했을 때보다 동시에 실행했을 때가 더 클 것이다.
테스트 과정
실험 1. [쿼리 단일 실행]
SELECT FOR UPDATE쿼리를 1개 실행, 실행 시간 측정
- 프로그램을 총 10번 실행하여 10번의 평균 실행 시간을 측정
- 인덱스 환경을 다르게 한 뒤 위 과정 반복
실험 2. [쿼리 다중 실행]
SELECT FOR UPDATE쿼리를 동시에 80개 실행, 80개 쿼리에 대한 평균 실행 시간 측정
- 프로그램을 총 10번 실행하여 10번의 평균 실행 시간을 측정
- 인덱스 환경을 다르게 한 뒤 위 과정 반복
테스트 결과
실험 1. [쿼리 단일 실행]
- (client_id) 인덱스만 있는 경우
| 실험 횟수 (회) | 실행 시간 (ms) |
| 1 | 97.06725 |
| 2 | 103.165292 |
| 3 | 102.57875 |
| 4 | 96.248876 |
| 5 | 74.439626 |
| 6 | 85.380541 |
| 7 | 84.22825 |
| 8 | 103.036209 |
| 9 | 89.68475 |
| 10 | 88.019583 |
| 평균 | 92.3849127 |
- (client_id, price) 인덱스만 있는 경우
| 실험 횟수 (회) | 실행 시간 (ms) |
| 1 | 89.830833 |
| 2 | 76.050875 |
| 3 | 76.871917 |
| 4 | 91.266958 |
| 5 | 77.87975 |
| 6 | 88.173333 |
| 7 | 97.214333 |
| 8 | 72.006792 |
| 9 | 76.423125 |
| 10 | 82.718292 |
| 평균 | 82.8436208 |
- (client_id) 인덱스가 있는 경우 실행 시간 평균: 92ms
- (client_id, price) 인덱스가 있는 경우 실행 시간 평균: 82ms
⇒ (client_id, price) 인덱스가 있는 경우 약 10% 개선
실험 2. [쿼리 다중 실행]
- (client_id) 인덱스만 있는 경우
| 실험 횟수 (회) | 평균 실행 시간 (ms) |
| 1 | 268.678285 |
| 2 | 279.777769 |
| 3 | 282.34414 |
| 4 | 256.563322 |
| 5 | 287.742817 |
| 6 | 286.537663 |
| 7 | 281.779033 |
| 8 | 309.243783 |
| 9 | 303.033227 |
| 10 | 259.926654 |
| 평균 | 281.562669 |
- (client_id, price) 인덱스만 있는 경우
| 실험 횟수 (회) | 평균 실행 시간 (ms) |
| 1 | 196.741081 |
| 2 | 257.475921 |
| 3 | 190.209282 |
| 4 | 191.498933 |
| 5 | 189.630351 |
| 6 | 194.879103 |
| 7 | 191.605002 |
| 8 | 194.102432 |
| 9 | 191.666292 |
| 10 | 183.326803 |
| 평균 | 198.11352 |
- (client_id) 인덱스가 있는 경우 평균 실행 시간 평균: 282ms
- (client_id, price) 인덱스가 있는 경우 평균 실행 시간 평균: 198ms
⇒ (client_id, price) 인덱스가 있는 경우 약 30% 개선
간단하게 테스트를 해보았을 때 가설이 들어 맞는 것을 확인할 수 있어요. 하지만 이 테스트가 정확한 테스트라고 하기에는 다른 변인이 명확히 통제되지 않았기 때문에 어려움이 있어요. 더 자세하게 테스트를 해보고 싶으시다면, 다른 변인도 통제하여 직접 테스트 해보시면 재미있을 것 같네요!
결론
현대의 대부분의 프로그램은 싱글 스레드로 기인되는, 그리고 싱글 스레드가 낼 수 있는 성능의 한계를 극복하기 위해 멀티 스레드를 이용하여 수평적으로 성능 향상을 꾀합니다. 하지만 결국 같은 작업을 여럿이 수행해야 한다는 것은 그들의 각자의 작업을 수행하며 벌어지는 충돌의 가능성을 내포하고 있어요.
따라서 어떻게 하면 성능에 문제가 되지 않으면서 여러 대상이 동시에 공유 자원에 접근할 수 있을지 많은 고민이 필요해요.